
VGG19 is a convolutional neural network (CNN) model that was developed by the Visual Geometry Group (VGG) at the University of Oxford. It is a deep learning model that has 19 layers, including 16 convolutional layers and 3 fully connected layers. VGG19 was introduced as a part of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2014 and achieved state-of-the-art results on the ImageNet dataset.
The VGG19 model is used for image classification, object recognition, and other computer vision tasks. It is a popular model in the deep learning community and has been used as a starting point for developing other CNN models. The model is trained on a large dataset of images and learns to extract features from the images through convolutional layers, which are then used to classify the image.
VGG19 has a simple architecture compared to some other deep learning models, which makes it easy to understand and implement. However, it has a large number of parameters, which can make it computationally expensive to train and use.
Here are some pros and cons of using the VGG19 model:
Pros:
- Accuracy: VGG19 has achieved state-of-the-art results on the ImageNet dataset and has been used as a benchmark model for image classification tasks.
- Transfer Learning: VGG19 has a large number of pre-trained models available, making it easy to use for transfer learning in other computer vision tasks.
- Simple architecture: The VGG19 architecture is relatively simple, making it easy to understand and implement.
- Feature extraction: The VGG19 model learns to extract rich features from the images, which can be useful in other computer vision tasks.
Cons:
- Large model size: VGG19 has a large number of parameters, which can make it computationally expensive to train and use.
- Limited to image classification: VGG19 is primarily used for image classification tasks, and may not perform as well in other computer vision tasks.
- Limited interpretability: Due to the complex nature of deep learning models, it can be difficult to understand how VGG19 arrives at its classifications.
- Limited flexibility: VGG19 has a fixed architecture, which may not be suitable for all computer vision tasks, and may require modifications or customizations.
VGG19 Architecture
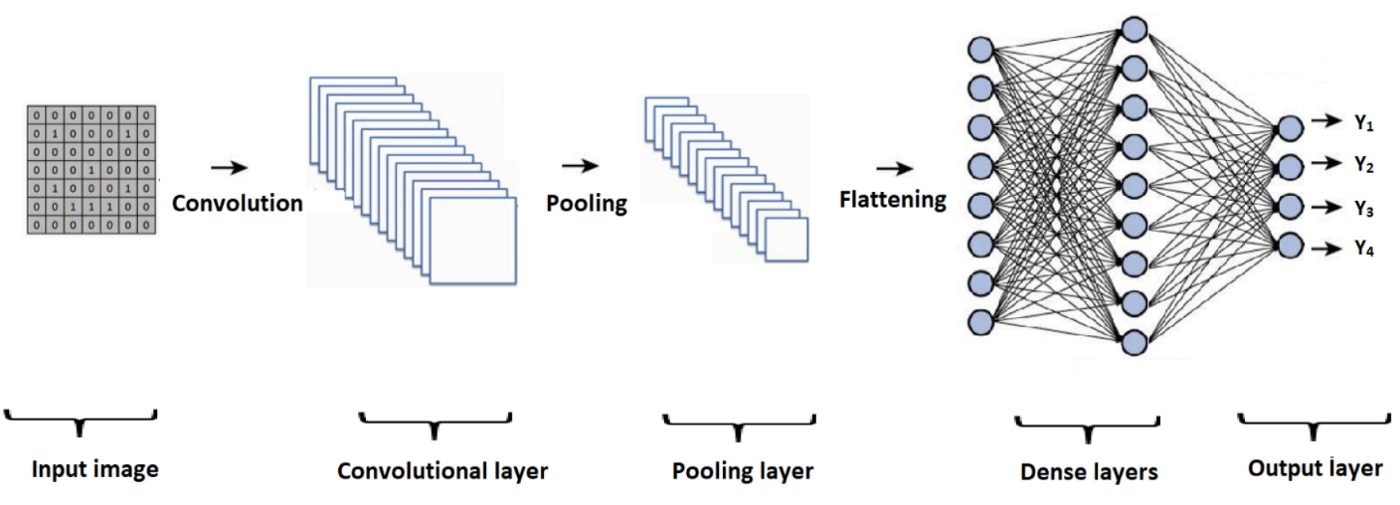
The VGG19 architecture consists of 19 layers, including 16 convolutional layers and 3 fully connected layers. The layers are arranged in sequential order, with each layer building on the previous layers. Here is a high-level overview of the VGG19 architecture:
- Input layer: The input layer takes in the input image, which is typically a 224x224x3 RGB image.
- Convolutional layers: There are 16 convolutional layers, each of which performs a convolution operation on the input image. The first two convolutional layers use 3×3 filters, while the remaining layers use 3×3 filters with padding to preserve the spatial dimensions of the input.
- Max pooling layers: There are 5 max pooling layers, which reduce the spatial dimensions of the feature maps.
- Fully connected layers: There are 3 fully connected layers, which perform a matrix multiplication operation on the feature maps to produce the final output. The first two fully connected layers have 4096 neurons each, while the last fully connected layer has 1000 neurons, representing the 1000 classes in the ImageNet dataset.
- Softmax activation: The output of the final fully connected layer is passed through a softmax activation function, which produces a probability distribution over the 1000 classes in the ImageNet dataset.
The VGG19 architecture has a relatively simple design, with a focus on depth and small filter sizes. The large number of parameters and the use of multiple layers with small filters enable the model to learn rich feature representations from the input images. The VGG19 model is widely used for image classification tasks and has achieved state-of-the-art performance on the ImageNet dataset.